

如果你也是个 Go 开发者,你是否关心过内存的分配和回收呢?创建的对象究竟需要由 GC 进行回收,还是随着调用栈被弹出,就消失了呢? GC 导致的 Stop The World 是否导致了你程序的性能抖动呢?
本文简单介绍了 Go 的内存分配逻辑,介绍了 Go 内存划分模型。并以代码为例子,简要介绍了几种场景下 Go 内存分配逻辑。随后使用go build 命令验证了内存逃逸等相关验证。最后,总结出了内存分配原则。
需要关心内存分配问题
每个工程师的时间都如此宝贵,在继续读这篇文章之前,需要你先回答几个问题,如果得到的答案是否定的,那可能本文章里写的内容对你并没有什么帮助。但是,如果你遇到了因内存分配而导致的性能问题,可能这篇文章能带你理解 Golang 的内存分配的冰山一角,带你入个门。
问题如下:
- 你的程序是性能敏感型吗?
- GC 带来的延迟影响到了你的程序性能吗?
- 你的程序有过多的堆内存分配吗?
如果你命中上面问题的其中一个或两个,那这篇文章适合你继续读下去。或你根本不知道如何回答这些问题,可能去了解下 go 性能观测相关的知识(pprof 的使用等)对你更有帮助。
下面正文开始。
Golang 简要内存划分
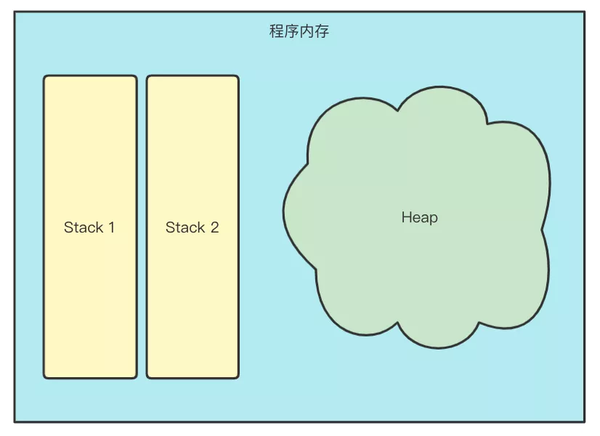
可以简单的认为 Golang 程序在启动时,会向操作系统申请一定区域的内存,分为栈(Stack)和堆(Heap)。栈内存会随着函数的调用分配和回收;堆内存由程序申请分配,由垃圾回收器(Garbage Collector)负责回收。性能上,栈内存的使用和回收更迅速一些;尽管Golang 的 GC 很高效,但也不可避免的会带来一些性能损耗。因此,Go 优先使用栈内存进行内存分配。在不得不将对象分配到堆上时,才将特定的对象放到堆中。
内存分配过程分析
本部分,将以代码的形式,分别介绍栈内存分配、指针作为参数情况下的栈内存分配、指针作为返回值情况下的栈内存分配并逐步引出逃逸分析和几个内存逃逸的基本原则。
正文开始,Talk is cheap,show me the code。
栈内存分配
我将以一段简单的代码作为示例,分析这段代码的内存分配过程。
代码的功能很简单,一个 main 函数作为程序入口,定义了一个变量n,定义了另一个函数 squire ,返回乘方操作后的 int 值。最后,将返回的值打印到控制台。程序输出为16。
下面开始逐行进行分析,解析调用时,go 运行时是如何对内存进行分配的。
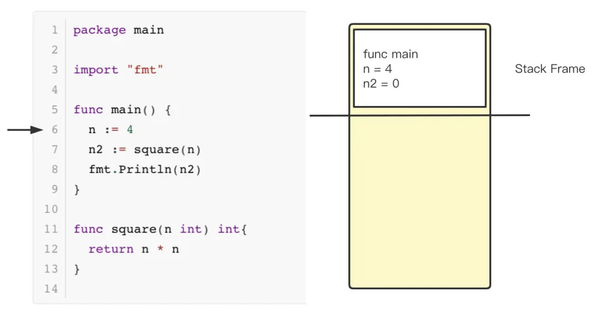
当代码运行到第6行,进入 main 函数时,会在栈上创建一个 Stack frame,存放本函数中的变量信息。包括函数名称,变量等。
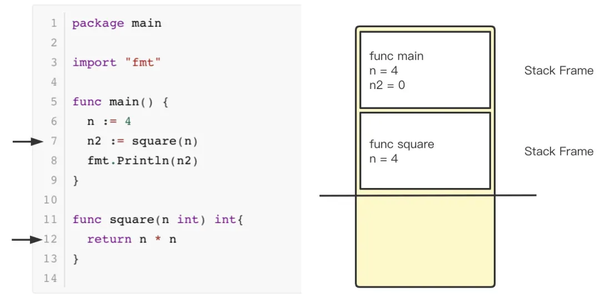

当代码运行到第7行时,go 会在栈中压入一个新的 Stack Frame,用于存放调用 square 函数的信息;包括函数名、变量 n 的值等。此时,计算4 * 4 的值,并返回。
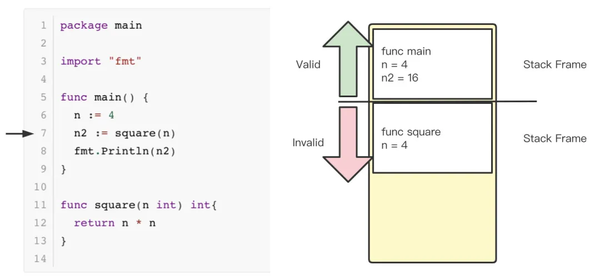
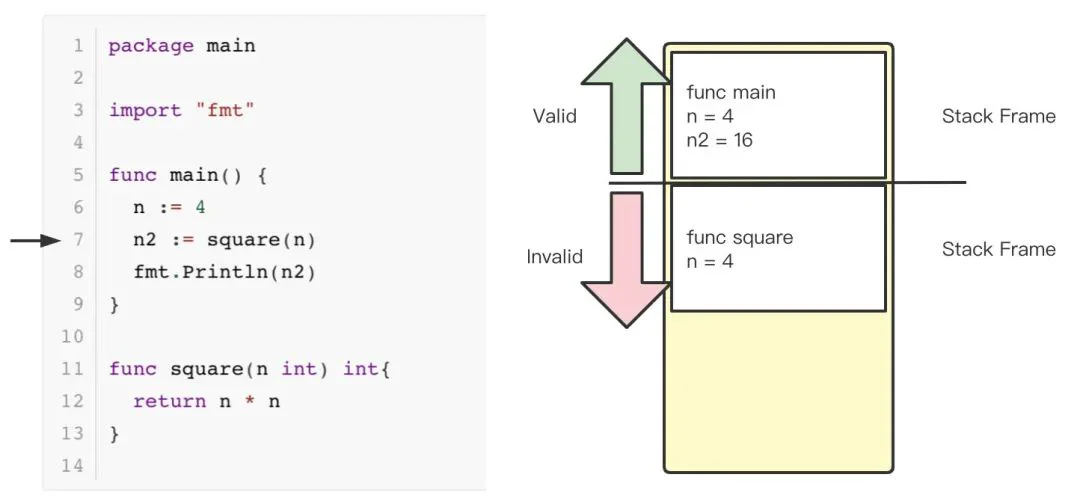
当 square 函数调用完成,返回16到 main 函数后,将16赋值给 n2变量。注意,原来的 stack frame 并不会被 go 清理掉,而是如栈左侧的箭头所示,被标记为不合法。上图夹在红色箭头和绿色箭头之间的横线可以理解为 go 汇编代码中的 SP 栈寄存器的值,当程序申请或释放栈内存时,只需要修改 SP 寄存器的值,这种栈内存分配方式省掉了清理栈内存空间的耗时【1】。
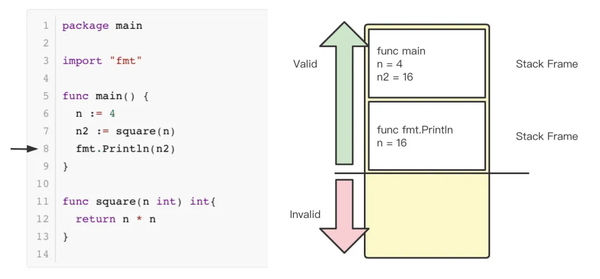
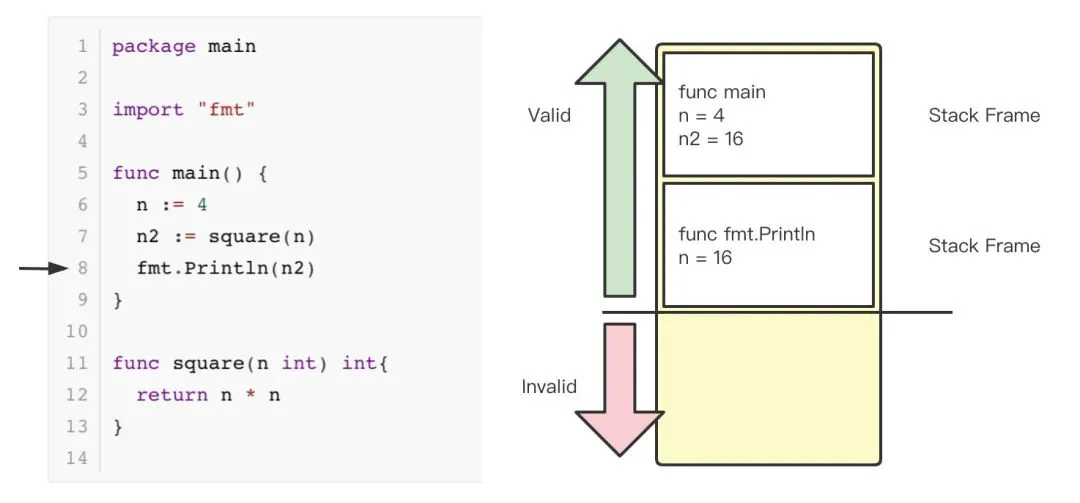
接下来,调用 fmt.Println 时,SP 寄存器的值会进一步增加,覆盖掉原来 square 函数的 stack frame,完成 print 后,程序正常退出。
指针作为参数情况下的栈内存分配
还是同样的过程,看如下这段代码。
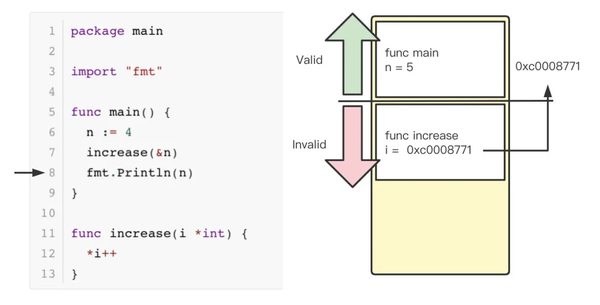
main 作为程序入口,声明了一个变量 n,赋值为4。声明了一个函数 increase,使用一个 int 类型的指针 i 作为参数,increase 函数内,对指针 i 对应的值进行自增操作。最后 main 函数中打印了 n 的值。程序输出为5。


当程序运行到 main 函数的第6行时,go 在栈上分配了一个 stack frame ,对变量 n 进行了赋值,n 在内存中对应的地址为0xc0008771,此时程序将继续向下执行,调用 increase 函数。


这时,increase 函数对应的 stack fream 被创建,i 被赋值为变量 n对应的地址值0xc0008771,然后进行自增操作。
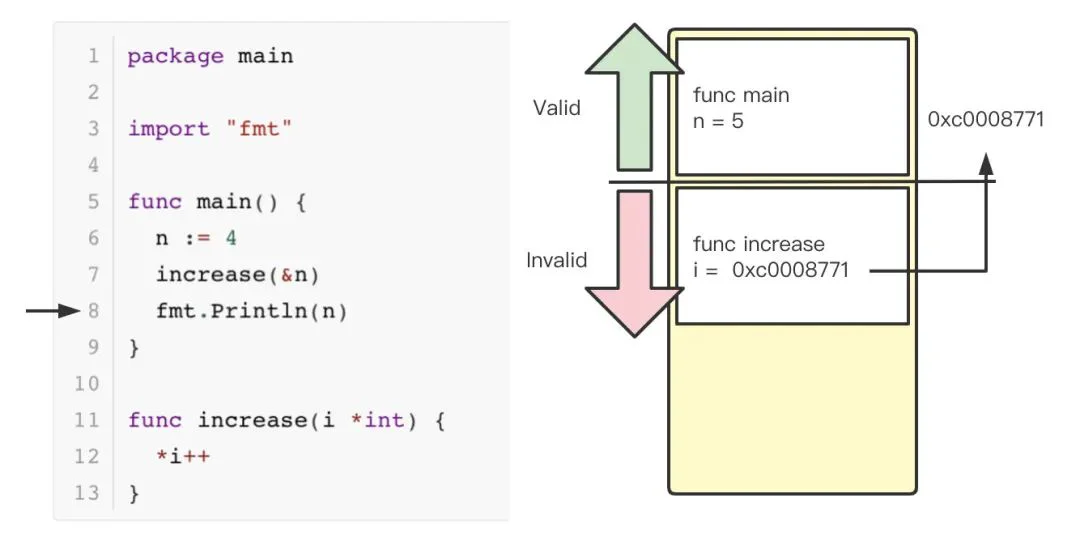
当 increase 函数运行结束后,SP 寄存器会上移,将之前分配的 stack freme 标记为不合法。此时,程序运行正常,并没有因为 SP 寄存器的改动而影响程序的正确性,内存中的值也被正确的修改了。
指针作为返回值情况下的栈内存分配
文章之前的部分分别介绍了普通变量作为参数和将指针作为参数情况下的栈内存使用,本部分来介绍将指针作为返回值,返回给调用方的情况下,内存是如何分配的,并引出内存逃逸相关内容。来看这段代码:
main 函数中,调用了 initValue 函数,该函数返回一个 int 指针并赋值给 n,指针对应的值为4。随后,main 函数调用 fmt.Println 打印了指针 n / 2对应的值。程序输出为2。
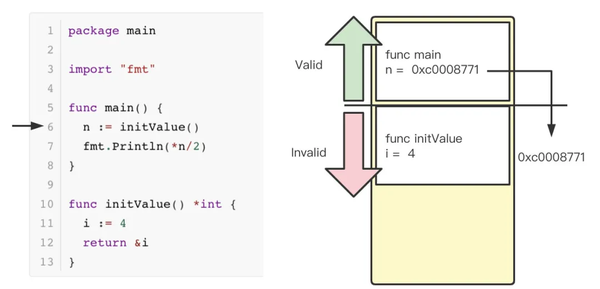
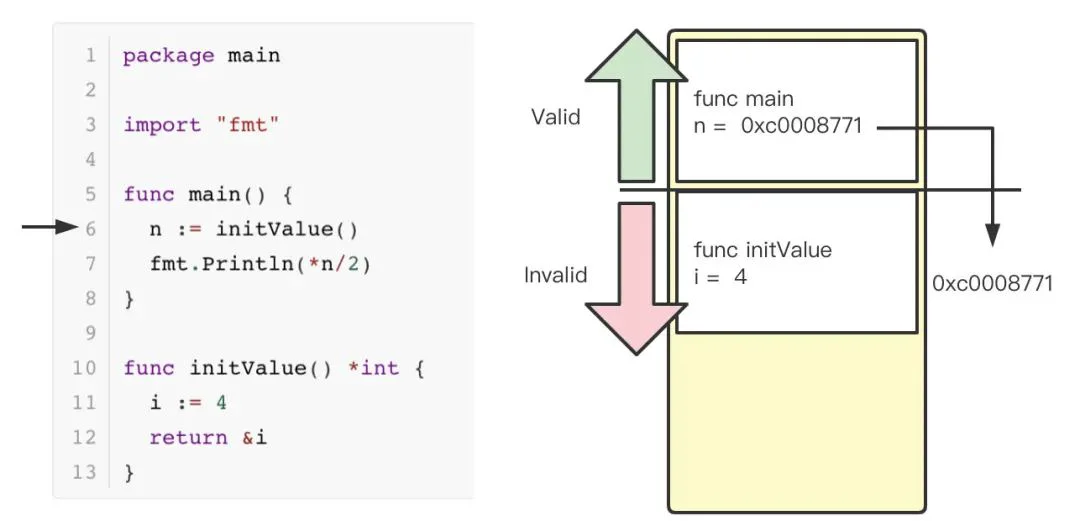
程序调用 initValue 后,将 i 的地址赋值给变量 n 。注意,如果这时,变量 i 的位置在栈上,则可能会随时被覆盖掉。
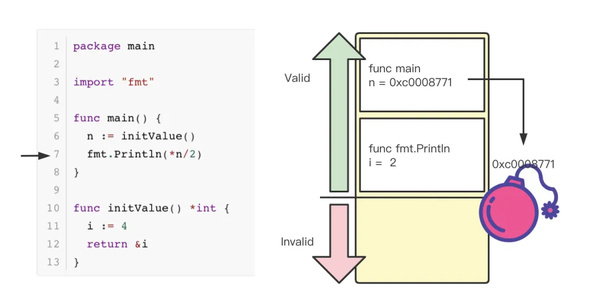
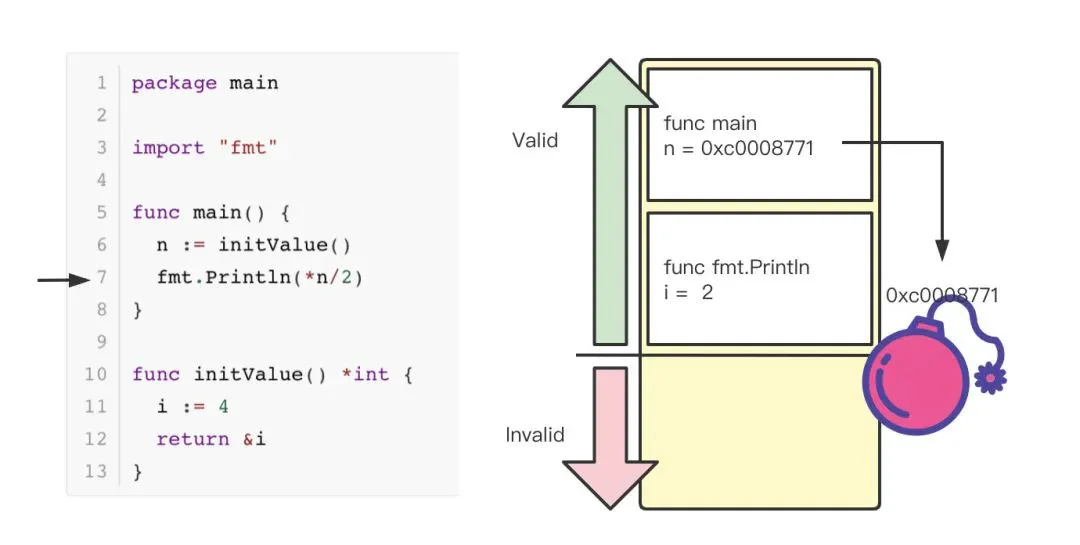
在调用 fmt.Println 时,Stack Frame 会被重新创建,变量 i 被赋值为*n/2也就是2,会覆盖掉原来 n 所指向的变量值。这会导致及其严重的问题。在面对 sharing up 场景时,go 通常会将变量分配到堆中,如下图所示:
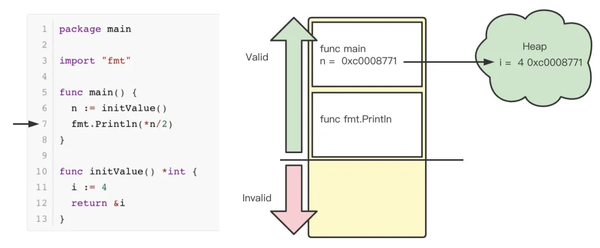
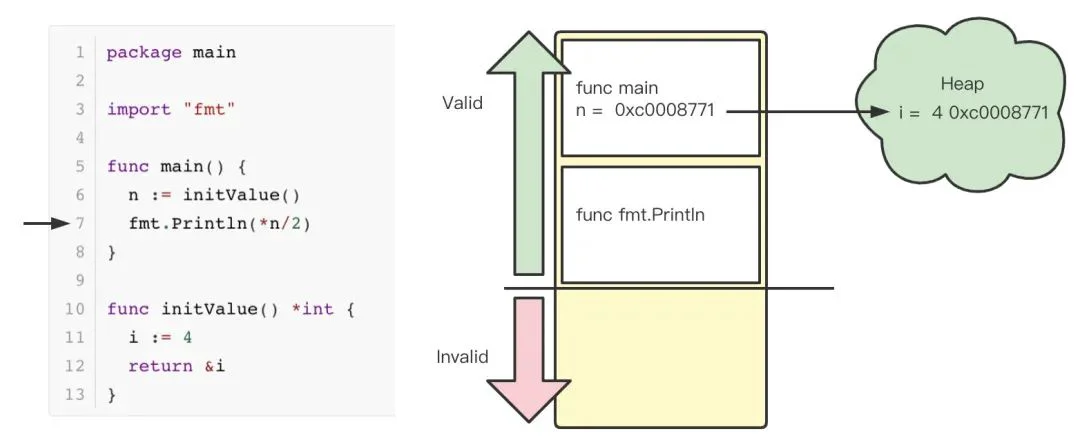
通过上面的分析,可以看到在面对被调用的函数返回一个指针类型时将对象分配到栈上会带来严重的问题,因此 Go 将变量分配到了堆上。这种分配方式保证了程序的安全性,但也不可避免的增加了堆内存创建,并需要在将来的某个时候,需要 GC 将不再使用的内存清理掉。
内存分配原则
经过上述分析,可以简单的归纳几条原则。
- Sharing down typically stays on the stack 在调用方创建的变量或对象,通过参数的形式传递给被调用函数,这时,在调用方创建的内存空间通常在栈上。这种在调用方创建内存,在被调用方使用该内存的“内存共享”方式,称之为 Sharing down。
- Sharing up typically escapes to the heap 在被调用函数内创建的对象,以指针的形式返回给调用方的情况下,通常,创建的内存空间在堆上。这种在被调用方创建,在调用方使用的“内存共享”方式,称之为 Sharing up。
- Only the compiler knows 之所以上面两条原则都加了通常,因为具体的分配方式,是由编译器确定的,一些编译器后端优化,可能会突破这两个原则,因此,具体的分配逻辑,只有编译器(或开发编译器的人)知道。
使用 go build 命令确定内存逃逸情况
值得注意的是,Go 在判断一个变量或对象是否需要逃逸到堆的操作,是在编译器完成的;也就是说,当代码写好后,经过编译器编译后,会在二进制中进行特定的标注,声明指定的变量要被分配到堆或栈。可以使用如下命令在编译期打印出内存分配逻辑,来具体获知特定变量或对象的内存分配位置。
查看 go help 可以看到 go build 其实是在调用 go tool compile。
其中,需要关心的参数有两个,
- -m 显示优化决策
- -l 禁止使用内联【2】
代码如下:
完整的构建命令和输出如下:
可以看到,sharing up 的情况(initValue,initObj,initFn)内存空间被分配到了堆上。sharing down 的情况(add)内存空间在栈上。
这里给读者留个问题,大家可以研究下 moved to heap 和 escapes to heap 的区别。
总结
1.因为栈比堆更高效,不需要 GC,因此 Go 会尽可能的将内存分配到栈上。
2.当分配到栈上可能引起非法内存访问等问题后,会使用堆,主要场景有:
- 当一个值可能在函数被调用后访问,这个值极有可能被分配到堆上。
- 当编译器检测到某个值过大,这个值会被分配到堆上。
- 当编译时,编译器不知道这个值的大小(slice、map...)这个值会被分配到堆上。
3.Sharing down typically stays on the stack
4.Sharing up typically escapes to the heap
5.Don't guess, Only the compiler knows