
一、golang 程序性能调优
在 golang 程序中,有哪些内容需要调试优化?
一般常规内容:
- cpu:程序对cpu的使用情况 - 使用时长,占比等
- 内存:程序对cpu的使用情况 - 使用时长,占比,内存泄露等。如果在往里分,程序堆、栈使用情况
- I/O:IO的使用情况 - 哪个程序IO占用时间比较长
golang 程序中:
- goroutine:go的协程使用情况,调用链的情况
- goroutine leak:goroutine泄露检查
- go dead lock:死锁的检测分析
- data race detector:数据竞争分析,其实也与死锁分析有关
上面是在 golang 程序中,性能调优的一些内容。
有什么方法工具调试优化 golang 程序?
比如 linux 中 cpu 性能调试,工具有 top,dstat,perf 等。
那么在 golang 中,有哪些分析方法?
golang 性能调试优化方法:
- Benchmark:基准测试,对特定代码的运行时间和内存信息等进行测试
- Profiling:程序分析,程序的运行画像,在程序执行期间,通过采样收集的数据对程序进行分析
- Trace:跟踪,在程序执行期间,通过采集发生的事件数据对程序进行分析
profiling 和 trace 有啥区别?
profiling 分析没有时间线,trace 分析有时间线。
在 golang 中,应用方法的工具呢?
这里介绍 pprof 这个 golang 工具,它可以帮助我们调试优化程序。
二、pprof 介绍
简介
pprof 是 golang 官方提供的性能调优分析工具,可以对程序进行性能分析,并可视化数据,看起来相当的直观。
当你的 go 程序遇到性能瓶颈时,可以使用这个工具来进行调试并优化程序。
本文将对下面 golang 中 2 个监控性能的包 pprof 进行运用:
上面的 pprof 开启后,每隔一段时间就会采集当前程序的堆栈信息,获取函数的 cpu、内存等使用情况。通过对采样的数据进行分析,形成一个数据分析报告。
pprof 以 profile.proto 的格式保存数据,然后根据这个数据可以生成可视化的分析报告,支持文本形式和图形形式报告。
profile.proto 里具体的数据格式是 protocol buffers。
那用什么方法来对数据进行分析,从而形成文本或图形报告?
go tool pprofpprof 使用模式
-
Report generation:报告生成
-
Interactive terminal use:交互式终端
-
Web interface:Web 界面
三、runtime/pprof
前提条件
go get github.com/google/pprof采样数据的方式:
// 开启 cpu 采集分析:
pprof.StartCPUProfile(w io.Writer)
// 停止 cpu 采集分析:
pprof.StopCPUProfile()
WriteHeapProfile 把内存 heap 相关的内容写入到文件中
pprof.WriteHeapProfile(w io.Writer)
- 第 2 种,在 benchmark 测试的时候
go test -cpuprofile cpu.prof -memprofile mem.prof -bench .
- 还有一种,对 http server 采集数据
go tool pprof $host/debug/pprof/profile
程序示例
go version go1.13.9
例子 1
我们用第 1 种方法,在程序中添加分析代码,demo.go :
package main
import (
"bytes"
"flag"
"log"
"math/rand"
"os"
"runtime"
"runtime/pprof"
"sync"
)
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to `file`")
var memprofile = flag.String("memprofile", "", "write mem profile to `file`")
func main() {
flag.Parse()
if *cpuprofile != "" {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal("could not create CPU profile: ", err)
}
defer f.Close()
if err := pprof.StartCPUProfile(f); err != nil {
log.Fatal("could not start CPU profile: ", err)
}
defer pprof.StopCPUProfile()
}
var wg sync.WaitGroup
wg.Add(200)
for i := 0; i < 200; i++ {
go cyclenum(30000, &wg)
}
writeBytes()
wg.Wait()
if *memprofile != "" {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal("could not create memory profile: ", err)
}
defer f.Close()
runtime.GC()
if err := pprof.WriteHeapProfile(f); err != nil {
log.Fatal("cound not write memory profile: ", err)
}
}
}
func cyclenum(num int, wg *sync.WaitGroup) {
slice := make([]int, 0)
for i := 0; i < num; i++ {
for j := 0; j < num; j++ {
j = i + j
slice = append(slice, j)
}
}
wg.Done()
}
func writeBytes() *bytes.Buffer {
var buff bytes.Buffer
for i := 0; i < 30000; i++ {
buff.Write([]byte{'0' + byte(rand.Intn(10))})
}
return &buff
}
编译程序、采集数据、分析程序:
- 编译 demo.go
go build demo.go
- 用 pprof 采集数据,命令如下:
./demo.exe --cpuprofile=democpu.pprof --memprofile=demomem.pprof
说明:我是 win 系统,这个 demo 就是 demo.exe ,linux 下是 demo
- 分析数据,命令如下:
go tool pprof democpu.pprof
go tool pprof [binary] [source]- binary: 是应用的二进制文件,用来解析各种符号
- source: 表示 profile 数据的来源,可以是本地的文件,也可以是 http 地址
go tool pprof --help注意:
获取的 Profiling 数据是动态获取的,如果想要获取有效的数据,需要保证应用或服务处于较大的负载中,比如正在运行工作中的服务,或者通过其他工具模拟访问压力。
否则如果应用处于空闲状态,比如 http 服务处于空闲状态,得到的结果可能没有任何意义。
(后面会遇到这种问题,http 的 web 服务处于空闲状态,采集显示的数据为空)
分析数据,基本的模式有 2 种:
- 一个是命令行交互分析模式
- 一个是图形可视化分析模式
命令行交互分析
A:命令行交互分析
go tool pprof democpu.pprof
| 字段 | 说明 |
|---|---|
| Type: | 分析类型,这里是 cpu |
| Duration: | 程序执行的时长 |
Duration 下面还有一行提示,这是交互模式(通过输入 help 获取帮助信息,输入 o 获取选项信息)。
可以看出,go 的 pprof 操作还有很多其他命令。
- 输入 help 命令,出来很多帮助信息:
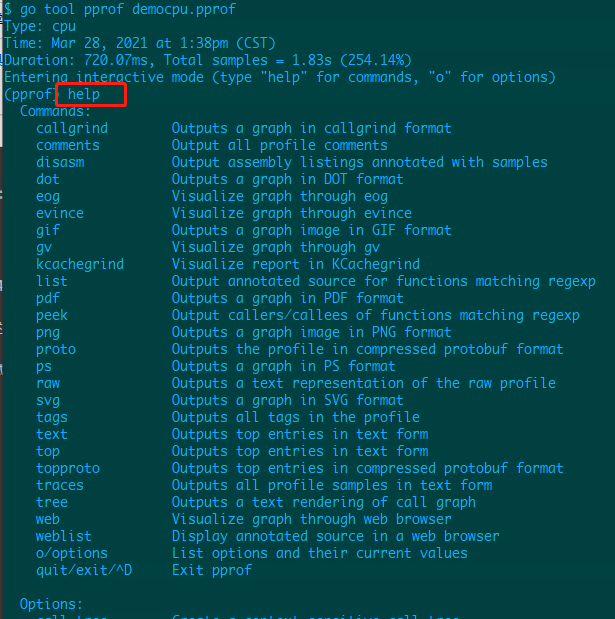
Commands 下有很多命令信息,text ,top 2个命令解释相同,输入这个 2 个看看:
- 输入 top,text 命令
top 命令:对函数的 cpu 耗时和百分比排序后输出
top后面还可以带参数,比如: top15
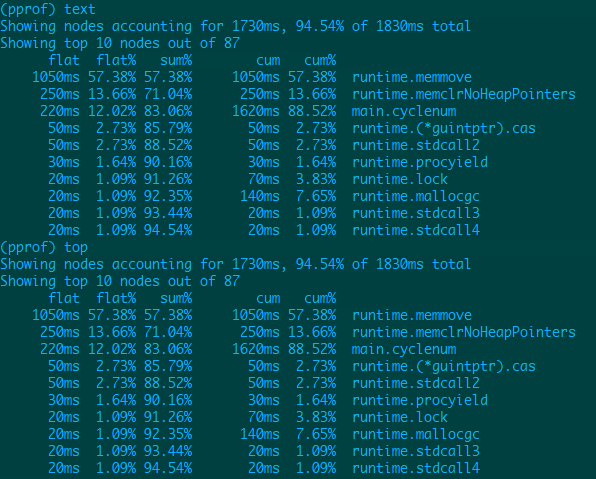
输出了相同的信息。
| 字段 | 说明 |
|---|---|
| flat | 当前函数占用 cpu 耗时 |
| flat % | 当前函数占用 cpu 耗时百分比 |
| sum% | 函数占用 cpu 时间累积占比,从小到大一直累积到 100% |
| cum | 当前函数加上调用当前函数的函数占用 cpu 的总耗时 |
| %cum | 当前函数加上调用当前函数的函数占用 cpu 的总耗时占比 |
listlist 命令:可以列出函数最耗时的代码部分,格式:list 函数名
main.cycylenumlist cyclenum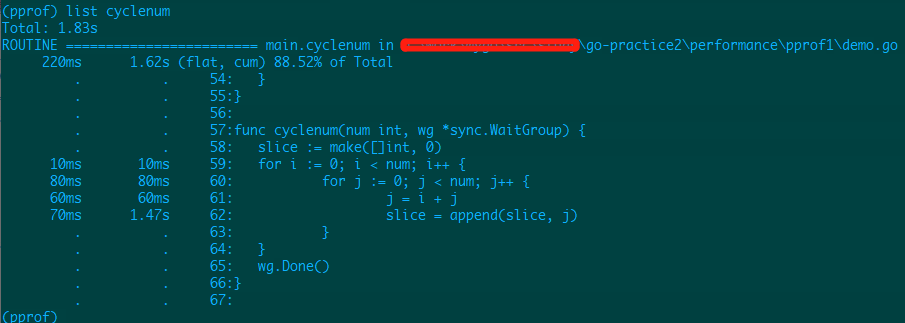
slice = append(slice, j)这里耗时的原因,应该是 slice 的实时扩容引起的。那我们空间换时间,固定 slice 的容量,make([]int, num * num)
B:命令行下直接输出分析数据
在命令行直接输出数据,基本命令格式为:
go tool pprof <format> [options] [binary] <source>
go tool pprof -text democpu.pprof可视化分析
A. pprof 图形可视化
除了上面的命令行交互分析,还可以用图形化来分析程序性能。
图形化分析前,先要安装 graphviz 软件,
dot -version生成可视化文件:
有 2 个步骤,根据上面采集的数据文件 democpu.pprof 来进行可视化:
- 命令行输入:go tool pprof democpu.pprof
- 输入 web 命令
在命令行里输入 web 命令,就可以生成一个 svg 格式的文件,用浏览器打开即可查看 svg 文件。
执行上面 2 个命令如下图:

用浏览器查看生成的 svg 图:

(文件太大,只截取了一小部分图,完整的图请自行生成查看)
关于图形的一点说明:
- 每个框代表一个函数,理论上框越大表示占用的 cpu 资源越多
- 每个框之间的线条代表函数之间的调用关系,线条上的数字表示函数调用的次数
- 每个框中第一行数字表示当前函数占用 cpu 的百分比,第二行数字表示当前函数累计占用 cpu 的百分比
B. web可视化-浏览器上查看数据
go tool pprof -http=:8080 democpu.pprof$ go tool pprof -http=:8080 democpu.pprof
Serving web UI on http://localhost:8080
http://localhost:8080/ui/go get -u github.com/google/pprofgo tool pprof -http=:8080 democpu.pprof还可以查看火焰图, http 地址:http://localhost:8080/ui/flamegraph,可直接点击 VIEW 菜单下的 Flame Graph 选项查看火焰图。当然还有其他选项可供选择,比如 Top,Graph 等等选项。你可以根据需要选择。
C. 火焰图 Flame Graph
其实上面的 web 可视化已经包含了火焰图,把火焰图集成到了 pprof 里。但为了向性能优化专家 Bredan Gregg 致敬,还是来体会一下火焰图生成过程。
火焰图 (Flame Graph) 是性能优化专家 Bredan Gregg 创建的一种性能分析图。Flame Graphs visualize profiled code。
火焰图形状如下:
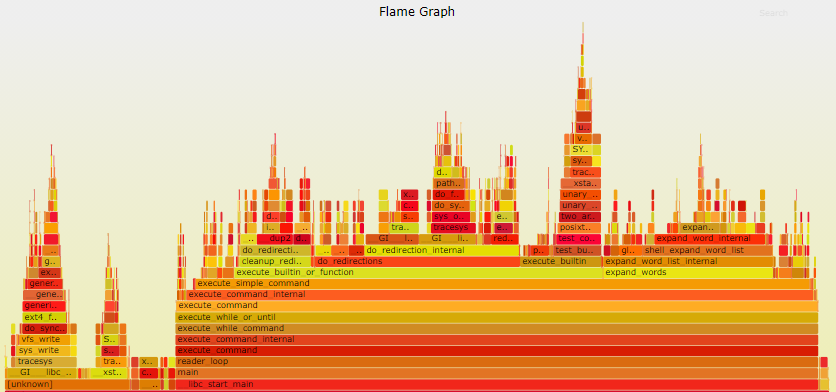
上面用 pprof 生成的采样数据,要把它转换成火焰图,就要使用一个转换工具 go-torch,这个工具是 uber 开源,它是用 go 语言编写的,可以直接读取 pprof 采集的数据,并生成一张火焰图, svg 格式的文件。
- 安装 go-torch:
go get -v github.com/uber/go-torch
- 安装 flame graph:
并把 FlameGraph 安装目录位置添加进 Path 中。
- 安装 perl 环境:
生成火焰图的程序 FlameGraph 是用 perl 写的,所以先要安装执行 perl 语言的环境。
perl -h
- 验证 FlameGraph 是否安装成功:
./flamegraph.pl --help
输出信息说明安装成功
- 生成火焰图:
重新进入到文件 democpu.pprof 的目录,然后执行命令:
go-torch -b democpu.pprof
上面命令默认生成名为 torch.svg 的文件,用浏览器打开查看:
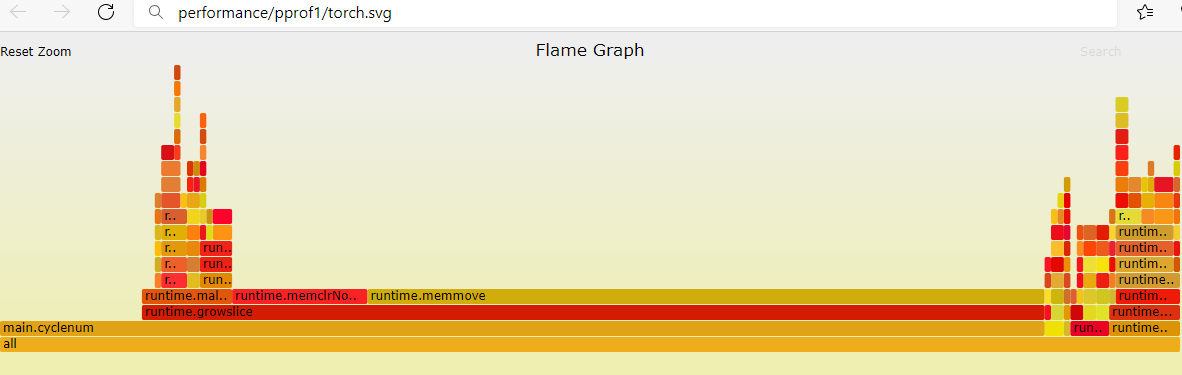
-fgo-torch -b democpu.pprof -f cpu_flamegraph.svg
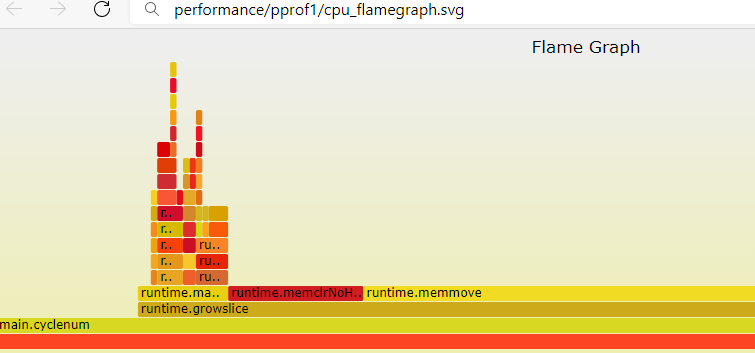
火焰图说明:
火焰图 svg 文件,你可以点击上面的每个方块来查看分析它上面的内容。
火焰图的调用顺序从下到上,每个方块代表一个函数,它上面一层表示这个函数会调用哪些函数,方块的大小代表了占用 CPU 使用时长长短。
go-torch 的命令格式:
go-torch [options] [binary] <profile source>
go-torch 帮助文档:
go-torch --help