
本文相应的代码附在文章末尾处。
场景描述
测试方法
测试结果
测试时条件设定:1000个生产消费对,每个生产者的生产间隔为50毫秒,总测试时长为1分钟。
1000 * 600 * 20 = 12000000实际任务情况:
| 类型 | 总生产任务数 | 总消费任务数 | 总丢弃任务数 |
|---|---|---|---|
| channel | 11964475 | 11964475 | 0 |
| cond | 11960068 | 11960068 | 0 |
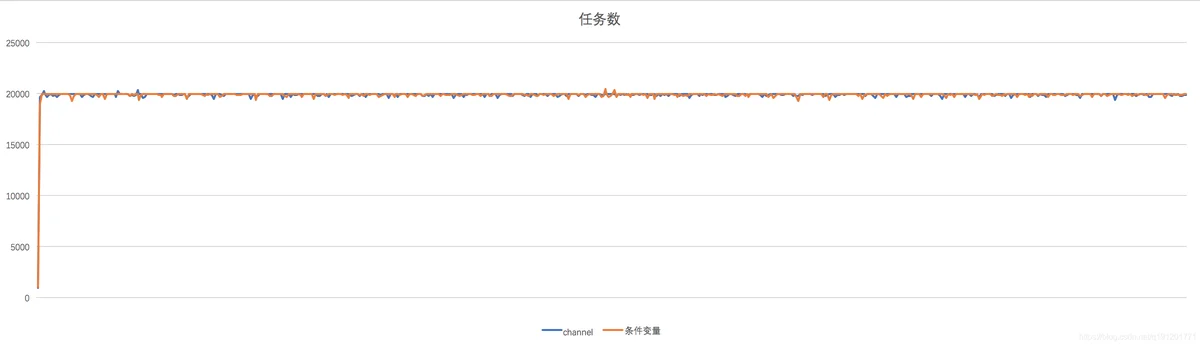
以下是每秒任务数随时间轴变化折线图:
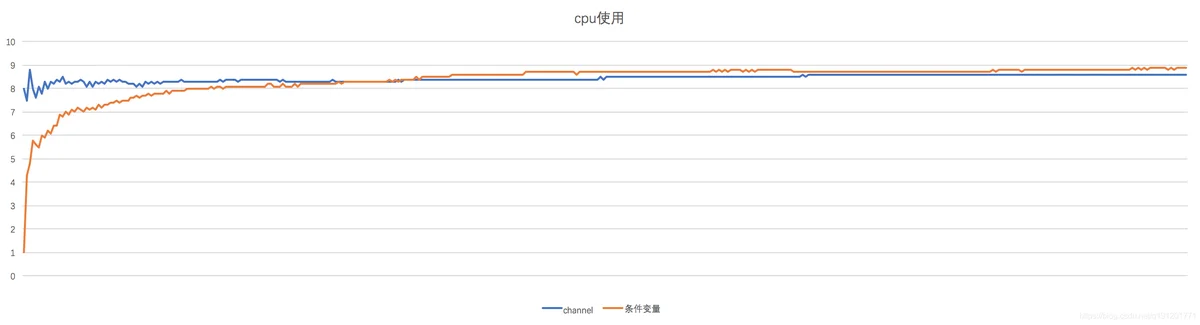
cpu使用对比
cpu平均使用率
- channel:8.44%
- cond:8.37%
以下是每秒cpu使用率随时间轴变化折线图:
测试代码
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
type Item struct {
index int // 生产消费对的编号
count int // 任务编号,在每个生产者中自增
}
var (
USING_CHANNEL bool = false // true 使用channel,false 使用cond
PAIR_NUM int = 1000 // 有多少对生产者消费者
QUEUE_NUM_CANCEL_PRODUCE int = 1000 // 生产时发现任务队列超过该值时,则丢弃该次生产的任务
PRODUCE_INTERVAL_MS int = 50 // 每个生产者的生产间隔
TEST_DURATION_SEC int = 600 // 总共测试时长
)
var gProduceCount int32 // 总生产任务数量
var gConsumeCount int32 // 总消费任务数量
var gDropCount int32 // 总生产时因任务队列超过阈值而丢弃的任务数量
func channelProduce(ch chan Item, index int) {
for i := 0; ; i++ {
if len(ch) > QUEUE_NUM_CANCEL_PRODUCE {
atomic.AddInt32(&gDropCount, 1)
fmt.Printf("cancel produce. index:%d len:%d\n", index, len(ch))
} else {
atomic.AddInt32(&gProduceCount, 1)
ch <- Item{index: index, count: i}
}
time.Sleep(time.Duration(PRODUCE_INTERVAL_MS) * time.Millisecond)
}
}
func channelConsume(ch chan Item, index int) {
for {
<-ch
atomic.AddInt32(&gConsumeCount, 1)
}
}
func condProduce(cond *sync.Cond, itemQueue *[]Item, index int) {
for i := 0; ; i++ {
cond.L.Lock()
if len(*itemQueue) > QUEUE_NUM_CANCEL_PRODUCE {
atomic.AddInt32(&gDropCount, 1)
fmt.Printf("cancel produce. index:%d len:%d\n", index, len(*itemQueue))
} else {
atomic.AddInt32(&gProduceCount, 1)
*itemQueue = append(*itemQueue, Item{index: index, count: i})
cond.Signal()
}
cond.L.Unlock()
time.Sleep(time.Duration(PRODUCE_INTERVAL_MS) * time.Millisecond)
}
}
func condConsume(cond *sync.Cond, itemQueue *[]Item, index int) {
for {
cond.L.Lock()
for len(*itemQueue) == 0 {
cond.Wait()
}
//fmt.Printf("index:%d item:(%d:%d)\n", index, (*itemQueue)[0].index, (*itemQueue)[0].count)
*itemQueue = (*itemQueue)[1:]
cond.L.Unlock()
atomic.AddInt32(&gConsumeCount, 1)
}
}
func trace() {
var prevProduceCount int32
var prevConsumeCount int32
for {
produceCount := atomic.LoadInt32(&gProduceCount)
consumeCount := atomic.LoadInt32(&gConsumeCount)
fmt.Printf("trace pc:%d cc:%d\n", produceCount-prevProduceCount, consumeCount-prevConsumeCount)
prevProduceCount = produceCount
prevConsumeCount = consumeCount
time.Sleep(time.Duration(1) * time.Second)
}
}
func main() {
fmt.Printf("using channel:%t\n", USING_CHANNEL)
for i := 0; i < PAIR_NUM; i++ {
if USING_CHANNEL {
ch := make(chan Item, QUEUE_NUM_CANCEL_PRODUCE*2)
go channelProduce(ch, i)
go channelConsume(ch, i)
} else {
cond := sync.NewCond(new(sync.Mutex))
var itemQueue []Item
go condProduce(cond, &itemQueue, i)
go condConsume(cond, &itemQueue, i)
}
}
go trace()
time.Sleep(time.Duration(TEST_DURATION_SEC) * time.Second)
produceCount := atomic.LoadInt32(&gProduceCount)
consumeCount := atomic.LoadInt32(&gConsumeCount)
dropCount := atomic.LoadInt32(&gDropCount)
fmt.Printf("produce count: %d, consume count: %d drop count: %d\n", produceCount, consumeCount, dropCount)
}
其他
对channel使用len获取当前大小是否线程安全
用len获取当前channel的大小是线程安全,但是由于获取大小、读取元素、写入元素是三个独立的操作,所以,获取了长度之后在做写入元素的操作时长度可能已经发生变化。
对于我们例子的场景,这种变化是可接受的。即在获取大小并判断得出已超过channel的生产阈值之后,消费协程可能又消费了一些元素,此时channel的大小可能比阈值要小,但我们依然丢弃当前元素的写入。
TODO
希望后续如果有时间有能力可以看看golang中channel的实现原理,slice的实现原理,container list的实现原理。