介绍
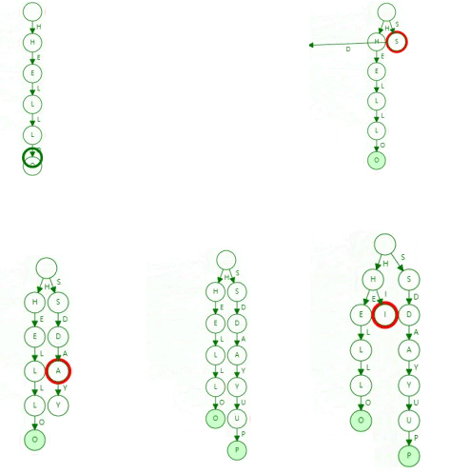
Trie树:又称为单词查找树,是一种树形结构,可以应用于统计字符串,会在搜索引擎系统中用于对文本的词频统计,下图是一个Trie树的结构,同时它也是在插入数时的一个顺序图.
流程
- 首先应该先创建一个结构体,里面保存的是每一个节点的信息
- 初始化根节点,根节点应该初始化啥?啥也不用初始化,给个空就好看上图
- 插入:串转字符数组;遍历数组,如果下一个节点为空,创建,则继续遍历
- 查找:串转字符数组,遍历如何所有字符都在树里面存在,并则最后一个字符Node中的end不为零,就视为存在
- 删除: 字符串转数组,遍历数组,在树上找到对应的字符,path-1
代码
在这个结构体里面有一个path,它的作用是啥呢?当有经过此字符的时候这个path就加一
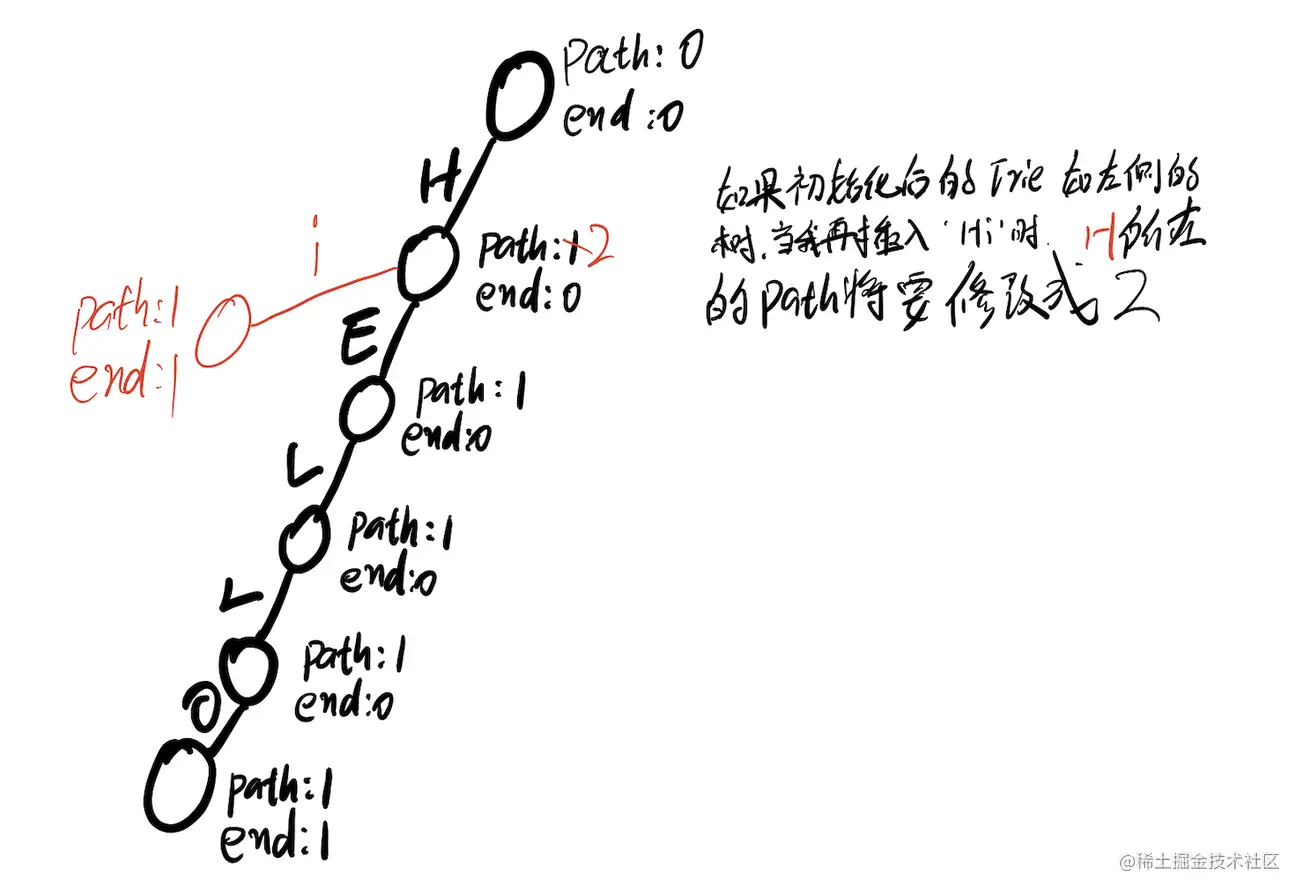
end又是干啥的呢?当一个单词的词尾是这个字符的时候end这个值就加一,就代表着这个字符做为一个单词的结尾
children是保存的啥呢?这个里面当然是保存的子节点啦,不用多说了叭~~~
初始化
初始化根节点,上面说过根节点里面是不用保存数据的,这个我就把里面的参数初始化成0,当然也可以不用初始化里面的参数,children这里就没有创建出来,因为下面我就要开始插入的操作了
插入
在插入之前先说一点:在传入的参数中,str我传入前我将其转换成了小写的,当然也可以转换成大写或者是大小写都有的
golangvalue-'a'children| 索引 | 字符 |
|---|---|
| 0 | a |
| 1 | b |
| 2 | c |
tempNode查找
ROOTtempNodetempNodeiftempNodeend
统计以XXX开头的单词个数
这个前缀树很强大,上面的解释也说到过,可以对文本的统计
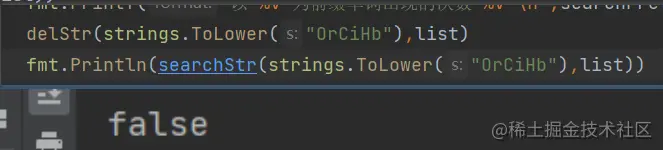
strArgs:=[]string{"qQYgMU","FFpdCl","nyyJmh","XJCebb","OrCiHb","xvDdzZ","nyCebF","hi","hello","nyyJmn"}
nPath
删除数据
删除数据的时候同样也是要遍历字符串,不过在此之前应该先查找一次这颗树里面有没有要删除的字符串,如果没有就直接return就好
path是当有字符经过的时候加一,那么在删除数据的时候只要查找到字符将这个字符串所经过的字符的path减1, 我这里还加了一个else,当path等于1的时候也就是说明当前所要删除的字符串是最后一个经过此字符的字符串,这里直接将其置空,等系统回收就好了