

当使用通用编程语言进行编写代码时,我们一定要知道代码是写给人看的,只是恰好可以被机器编译和执行,而很难被人理解的代码是非常糟糕并且不容易维护的。代码其实就是按照约定格式编写的一堆字符串,经过训练的软件工程师可以在脑内对语言的源代码进行编译并运行目标程序,我们能对本来无意义的字符串进行分组和分析,按照约定的语法来理解源代码。
既然工程师能够按照一定的方式理解和编译 Go 语言的源代码,那么我们如何模拟人理解源代码的方式构建一个能够分析编程语言代码的程序呢。我们在这一节中将介绍词法分析和语法分析这两个重要的编译过程,这两个过程能将原本机器看来无序意义的源文件转换成更容易理解、分析并且结构化的抽象语法树,接下来我们就看一看解析器眼中的 Go 语言是什么样的。
1. 词法分析
源代码在编译器眼中其实就是一团乱麻,一个由『无实际意义』字符组成的、无法被理解的字符串,所有的字符在编译器看来并没有什么区别,为了理解这些字符我们需要做的第一件事情就是将字符串分组,这样能够降低理解字符串的成本,简化分析源代码的过程。
make(chan int)makechanintlex
lex3 是用于生成词法分析器的工具,lex 生成的代码能够将一个文件中的字符分解成 Token 序列,很多语言在设计早期都会使用它快速设计出原型。词法分析作为具有固定模式的任务,出现这种更抽象的工具其实是必然的,lex 作为一个代码生成器,使用了类似 C 语言的语法,我们可以理解成 lex 使用正则匹配对输入的字符流进行扫描,下面是一个 lex 文件的示例:
%{
#include <stdio.h>
%}
%%
package printf("PACKAGE ");
import printf("IMPORT ");
. printf("DOT ");
{ printf("LBRACE ");
} printf("RBRACE ");
( printf("LPAREN ");
) printf("RPAREN ");
" printf("QUOTE ");
n printf("n");
[0-9]+ printf("NUMBER ");
[a-zA-Z_]+ printf("IDENT ");
%%packageimportpackage main
import (
"fmt"
)
func main() {
fmt.Println("Hello")
}.llexsimplego.l$ lex simplego.l
$ cat lex.yy.c
...
int yylex (void) {
...
while ( 1 ) {
...
yy_match:
do {
register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)];
if ( yy_accept[yy_current_state] ) {
(yy_last_accepting_state) = yy_current_state;
(yy_last_accepting_cpos) = yy_cp;
}
while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state ) {
yy_current_state = (int) yy_def[yy_current_state];
if ( yy_current_state >= 30 )
yy_c = yy_meta[(unsigned int) yy_c];
}
yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c];
++yy_cp;
} while ( yy_base[yy_current_state] != 37 );
...
do_action:
switch ( yy_act )
case 0:
...
case 1:
YY_RULE_SETUP
printf("PACKAGE ");
YY_BREAK
...
}yylexwhilemainmain-ll$ cc lex.yy.c -o simplego -ll
$ cat main.go | ./simplego当我们将 C 语言代码通过 gcc 编译成二进制代码之后,就可以使用管道将上面提到的 Go 语言代码作为输入传递到生成的词法分析器中,这个词法分析器会打印出如下的内容:
PACKAGE IDENT
IMPORT LPAREN
QUOTE IDENT QUOTE
RPAREN
IDENT IDENT LPAREN RPAREN LBRACE
IDENT DOT IDENT LPAREN QUOTE IDENT QUOTE RPAREN
RBRACE从上面的输出我们能够看到 Go 源代码的影子,lex 生成的词法分析器 lexer 通过正则匹配的方式将机器原本很难理解的字符串进行分解成很多的 Token,有利于后面的继续处理。

.llex.llexGo
src/cmd/compile/internal/syntax/scanner.goscannertype scanner struct {
source
mode uint
nlsemi bool
// current token, valid after calling next()
line, col uint
tok token
lit string
kind LitKind
op Operator
prec int
}src/cmd/compile/internal/syntax/tokens.gotokenconst (
_ token = iota
_EOF // EOF
// operators and operations
_Operator // op
// ...
// delimiters
_Lparen // (
_Lbrack // [
// ...
// keywords
_Break // break
// ...
_Type // type
_Var // var
tokenCount //
)scannernextswitch/casefunc (s *scanner) next() {
c := s.getr()
for c == ' ' || c == 't' || c == 'n' || c == 'r' {
c = s.getr()
}
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
case -1:
s.tok = _EOF
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ...
}
}scannergetr0numberfunc (s *scanner) number(c rune) {
s.startLit()
s.kind = IntLit
for isDigit(c) {
c = s.getr()
}
s.ungetr()
s.nlsemi = true
s.lit = string(s.stopLit())
s.tok = _Literal
}numberstartLitscannerungetrscannerscannernextnextGo 语言的词法元素相对来说还是比较简单,使用这种巨大的 switch/case 进行词法解析也比较方便和顺手,早期的 Go 语言虽然使用 lex 这种工具来生成词法解析器,但是最后还是使用 Go 来实现词法分析器,用自己写的词法分析器来解析自己8。
2. 语法分析
说完了编译最开始的词法分析过程,接下来就到了语法分析,语法分析是根据某种特定的形式文法(Grammar)对 Token 序列构成的输入文本进行分析并确定其语法结构的一种过程9。从上面的定义来看,词法分析器输出的结果 — Token 序列就是语法分析器的输入。
在语法分析的过程会使用自顶向下或者自底向上的方式进行推导,在介绍 Go 语言的语法分析的实现原理之前,我们会先来介绍语法分析中的文法和分析方法。
文法
上下文无关文法是用来对某种编程语言进行形式化的、精确的描述工具,我们能够通过文法定义一种语言的语法,它主要包含了一系列用于转换字符串的生产规则(production rule)10。上下文无关文法中的每一个生产规则都会将规则左侧的非终结符转换成右侧的字符串,文法都由以下的四个部分组成:
终结符是文法中无法再被展开的符号,而非终结符与之相反,还可以通过生产规则进行展开,例如 “id”、“123” 等标识或者字面量11。
- NN 有限个非终结符的集合;
- ΣΣ 有限个终结符的集合;
- PP 有限个生产规则12的集合;
- SS 非终结符集合中唯一的开始符号;
文法被定义成一个四元组 (N,Σ,P,S)(N,Σ,P,S),这个元组中的几部分就是上面提到的四个符号,其中最为重要的就是生产规则了,每一个生产规则都会包含非终结符、终结符或者开始符号,我们在这里可以举一个简单的例子:
- S→aSbS→aSb
- S→abS→ab
abaabbaaa..bbbsrc/cmd/compile/internal/syntax/parser.goSourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) .
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Declaration = ConstDecl | TypeDecl | VarDecl .Go 语言更详细的文法可以从 Language Specification14 中找到,这里不仅包含语言的文法,还包含词法元素、内置函数等信息。
SourceFileSourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .SourceFilepackageimportSourceFileFiletype File struct {
PkgName *Name
DeclList []Decl
Lines uint
node
}src/cmd/compile/internal/syntax/parser.goConstDecl = "const" ( ConstSpec | "(" { ConstSpec ";" } ")" ) .
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
TypeDecl = "type" ( TypeSpec | "(" { TypeSpec ";" } ")" ) .
TypeSpec = AliasDecl | TypeDef .
AliasDecl = identifier "=" Type .
TypeDef = identifier Type .
VarDecl = "var" ( VarSpec | "(" { VarSpec ";" } ")" ) .
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .consttypevarStatementFunctionDecl = "func" FunctionName Signature [ FunctionBody ] .
FunctionName = identifier .
FunctionBody = Block .
MethodDecl = "func" Receiver MethodName Signature [ FunctionBody ] .
Receiver = Parameters .
Block = "{" StatementList "}" .
StatementList = { Statement ";" } .
Statement =
Declaration | LabeledStmt | SimpleStmt |
GoStmt | ReturnStmt | BreakStmt | ContinueStmt | GotoStmt |
FallthroughStmt | Block | IfStmt | SwitchStmt | SelectStmt | ForStmt |
DeferStmt .
SimpleStmt = EmptyStmt | ExpressionStmt | SendStmt | IncDecStmt | Assignment | ShortVarDecl .Statementsrc/cmd/compile/internal/syntax/parser.go分析方法
语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
- 自顶向下分析:可以被看作找到当前输入流最左推导的过程,对于任意一个输入流,根据当前的输入符号,确定一个生产规则,使用生产规则右侧的符号替代相应的非终结符向下推导15;
- 自底向上分析:语法分析器从输入流开始,每次都尝试重写最右侧的多个符号,这其实就是说解析器会从最简单的符号进行推导,在解析的最后合并成开始符号16;
如果读者无法理解上述的定义也没有关系,我们会在这一节的剩余部分介绍两种不同的分析方法以及它们的具体分析过程。
自顶向下
LL 文法17就是一种使用自顶向下分析方法的文法,下面给出了一个常见的 LL 文法:
- S→aS1S→aS1
- S1→bS1S1→bS1
- S1→ϵS1→ϵ
abb- SS (开始符号)
- aS1aS1(规则 1)
- abS1abS1(规则 2)
- abbS1abbS1(规则 2)
- abbabb(规则 3)
这种分析方法一定会从开始符号分析,通过下一个即将入栈的符号判断应该如何对当前堆栈中最右侧的非终结符(SS 或 S1S1)进行展开,直到整个字符串中不存在任何的非终结符,整个解析过程才会结束。
自底向上
但是如果我们使用自底向上的方式对输入流进行分析时,处理过程就会完全不同了,常见的四种文法 LR(0)、SLR、LR(1) 和 LALR(1) 使用了自底向上的处理方式18,我们可以简单写一个与上一节中效果相同的 LR(0) 文法:
- S→S1S→S1
- S1→S1bS1→S1b
- S1→aS1→a
abb- aa(入栈)
- S1S1(规则 3)
- S1bS1b(入栈)
- S1S1(规则 2)
- S1bS1b(入栈)
- S1S1(规则 2)
- SS(规则 1)
自底向上的分析过程会维护一个堆栈用于存储未被归约的符号,在整个过程中会执行两种不同的操作,一种叫做入栈(shift),也就是将下一个符号入栈,另一种叫做归约(reduce),也就是对最右侧的字符串按照生产规则进行合并。
上述的分析过程和自顶向下的分析方法完全不同,这两种不同的分析方法其实也代表了计算机科学中两种不同的思想 — 从抽象到具体和从具体到抽象。
Lookahead
在语法分析中除了 LL 和 LR 这两种不同类型的语法分析方法之外,还存在另一个非常重要的概念,就是向前查看(Lookahead),在不同生产规则发生冲突时,当前解析器需要通过预读一些 Token 判断当前应该用什么生产规则对输入流进行展开或者归约19,例如在 LALR(1) 文法中,就需要预读一个 Token 保证出现冲突的生产规则能够被正确处理。
Go
Go 语言的解析器就使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列20,最右推导加向前查看构成了 Go 语言解析器的最基本原理,也是大多数编程语言的选择。
parseFilesParseparserfileOrNilfunc Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}fileOrNilpackage// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File {
f := new(File)
f.pos = p.pos()
if !p.got(_Package) {
p.syntaxError("package statement must be first")
return nil
}
f.PkgName = p.name()
p.want(_Semi)gotpackagepackagenamefor p.got(_Import) {
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
p.want(_Semi)
}importimportDeclListappendGroupconstDecltypeDeclfor p.tok != _EOF {
switch p.tok {
case _Const:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
}
}
f.Lines = p.source.line
return f
}fileOrNilFilescannerparserp.next()scannernextfileOrNilfileOrNilimportDeclconstDecl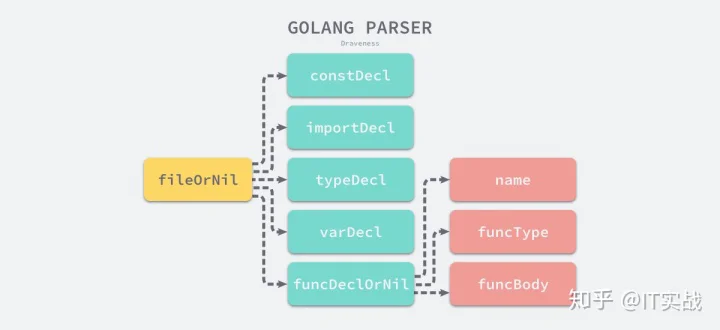
fileOrNilconstDeclfileOrNilSourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .parserfileOrNilsrc/cmd/compile/internal/syntax/parser.go辅助方法
gotwantfunc (p *parser) got(tok token) bool {
if p.tok == tok {
p.next()
return true
}
return false
}
func (p *parser) want(tok token) {
if !p.got(tok) {
p.syntaxError("expecting " + tokstring(tok))
p.advance()
}
}gottruewantgot这两个方法的引入能够帮助工程师在上层减少判断关键字的大量重复逻辑,让上层语法分析过程的实现更加清晰。
appendGroupvar (
a int
b int
)ConstDeclVarDeclGroupappendGroupfunc (p *parser) appendGroup(list []Decl, f func(*Group) Decl) []Decl {
if p.tok == _Lparen {
g := new(Group)
p.list(_Lparen, _Semi, _Rparen, func() bool {
list = append(list, f(g))
return false
})
} else {
list = append(list, f(nil))
}
return list
}appendGroupfFileDeclListimportconstvartypefuncappendGroup节点
Filetype File struct {
PkgName *Name
DeclList []Decl
Lines uint
node
}src/cmd/compile/internal/syntax/nodes.gotype (
Decl interface {
Node
aDecl()
}
FuncDecl struct {
Attr map[string]bool
Recv *Field
Name *Name
Type *FuncType
Body *BlockStmt
Pragma Pragma
decl
}
}BlockStmt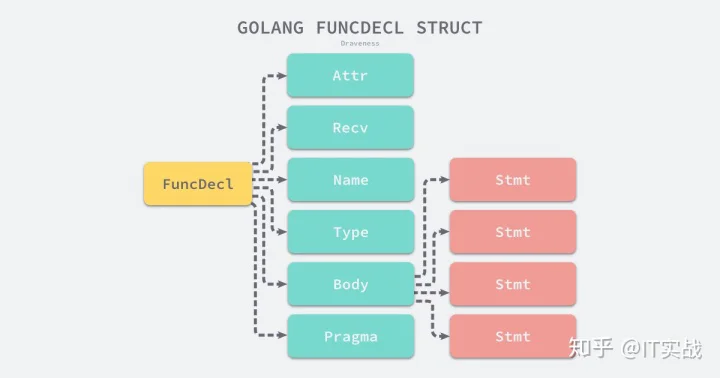
StmtStmtStmt
Stmtifforswitchselect3. 小结
这一节介绍了 Go 语言的词法分析和语法分析过程,我们不仅从理论的层面介绍了词法和语法分析的原理,还从 Golang 的源代码出发详细分析 Go 语言的编译器是如何在底层实现词法和语法解析功能的。
scannerparser全套教程点击下方链接直达:
IT实战:Go语言设计与实现自学教程zhuanlan.zhihu.com